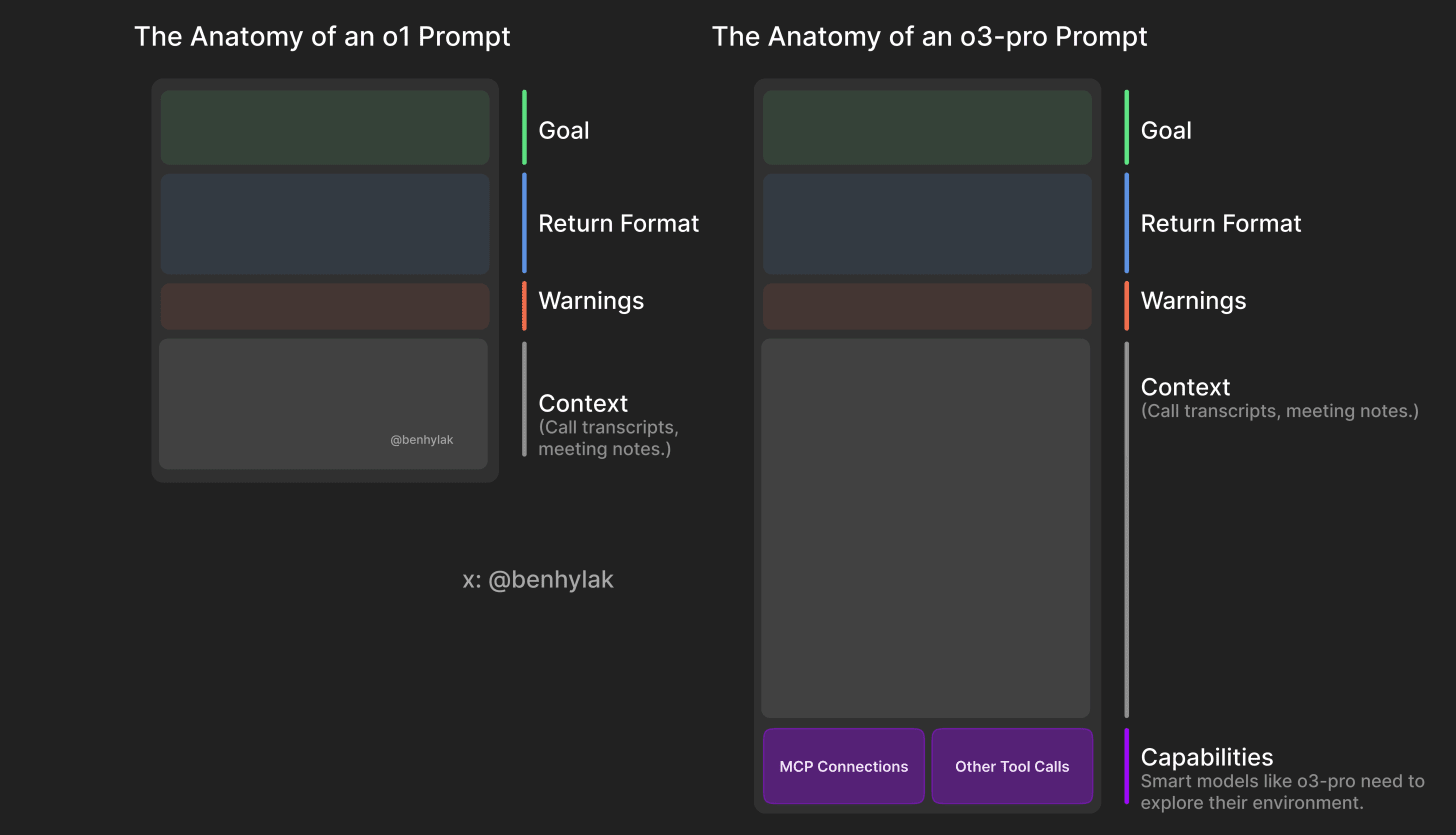
- Evaluation method: with traditional benchmark ability not to assess
- # assessment example: corporate strategic planning mission
- O3Pro Key Strength Summary
- Model comparison: different from the same model
- <a href=”/tags/openai.html’ | prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a>’s walking vertically reinforced learning path
- Use of Recommendations and Best Practices
- # with hint advice:
- Let’s wrap it up
- God yearns for context: the first impression of o3Pro
- It’s the era of mission-specific models.
- The key I found was: ** Don’t “talk” it **.
- It’s smarter, really smarter.
- It’s hard to see through evaluation.
- Today’s “integration” depends mainly on tools:
- o3 pro (left) vs o3 (right):
- From early use:
- How to hint that the reasoning model hasn’t changed:
- Other fragmentary observations:
| Ben Hylak’s unique assessment of <a href=”/tags/openai.html’ | prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a>’s latest o3pro model |
Positioning # o3Pro: Task-level SuperRisk Assistant
-
Task-specific models: Different from daily chat models (e.g. GPT-3.5, GPS-4o);
-
O3 Pro is designed as: For complex tasks, deep analysis, highly rational, calm, non-dialogue-type, more like an “executor analyst” or “strategy strategist”
Evaluation method: with traditional benchmark ability not to assess
** Author’s assessment strategy:**
-
Non-dialogue testing;
-
Observe its** ability to address complex tasks and the quality of output of specific implementation recommendations**.
# assessment example: corporate strategic planning mission
-
Author of Rainrop: Records of all planning meetings;
-
Long-term/short-term objectives;
-
Voice memorandum;
-
Team history.
Unified feed to o3Pro, proposing: “Please provide a strategic operational plan for the next phase”. ** Output result:**
-
O3Pro gives: Accurate target indicators (target metrics);
-
A clear time line (timelines);
-
Strict priority (priority);
-
Items proposed for deletion (cut list);
The high quality of the output** prompted the team to change its strategic direction**.
O3Pro Key Strength Summary
1. High level of intelligence, but need to be “fed with context”
-
Is not suitable for short prompt tests;
-
The need for “many background + clear objectives” for performance;
-
Not necessarily for casual chats.
2. Strong environmental perception and tool interaction
-
Be able to judge whether ** or not external tools are required**;
-
Not to fabricate unaccessible information, but to give a clear indication of the need for “you tell it”;
-
Very good at dispatching, using external functions, API, database, etc.
3. System alerts and context are extremely important
-
system prompt has far-reaching implications for their conduct;
-
For example, “You’re a product manager” vs. “You’re a safety expert” will produce a very different style and strategy.
4. Potential weaknesses: easy to over-analyse in low context
-
Inadequate contextualization can lead to “excessive thinking” and can easily fall into the dead end of reasoning;
-
“Direct action type” tasks (e.g. SQL queries) may not be as flexible as basic models.
Model comparison: different from the same model

<a href=”/tags/openai.html’ | prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a>’s walking vertically reinforced learning path
-
<a href=”/tags/openai.html’ prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a> not only teaches the model “How to Call Tools” but also “When to Call Tools”; -
The advancement of LLM, which is one of the key routes for determining the timing of the use of tools, as is the case with humans,** common artificial intelligence;
- O3 Pro is the product of this strategy.
Use of Recommendations and Best Practices
# with hint advice:
Context is king:
-
Relevant documents, targets, role descriptions should be included in the reminder;
-
Like, “ Feed cookies to cookie biscuits.”
** Clear objectives**:
- Do not say “let me write something” but say “let me write a three-phase product online strategy based on the following data”.
Enhanced system hint:
- Role setting in system alerts and mission statements have a significant impact on the model’s “behavior style”.
Let’s wrap it up
O3Pro’s not your “talking” friend, he’s your company’s top-level strategic analyst. Below is the full Chinese translation of ** God is hungry for Context: First thoughts on o3 pro**:
God yearns for context: the first impression of o3Pro
This post is part of our special coverage Egypt Protests 2011.
As stated in Leakage, <a href=”/tags/openai.html’ | prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a> has today reduced the price of o3 by 80% (from $10/$40 per million token to $2/$8 — equal to GPT-4.1!) to pave the way for the introduction of o3-pro ($20/$80), which supports an unverified community theory that the pro variant is a 10-fold call for the base model and uses a majority voting mechanism (referred to in the <a href=”/tags/openai.html’ | prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a> paper and in our Chai programme).
O3-Pro defeated o3 in human tests with **64% ** and slightly outnumbered 4 reliability benchmark tests. But, as Sam Altman pointed out, the actual experience becomes real when you test it in a “different way” .
In the past week, I’ve gained an early access to o3 pro. Here are some of my (early) thoughts:

It’s the era of mission-specific models.
On the one hand, we have “normal” models like GPT-3.5 Sonnet and GPT-4o – talking like friends, helping us write, answering everyday questions. On the other hand, we have the large, slow, expensive and intellectually motivated models that specialize in in-depth analysis, one-off solutions to complex problems and explore purely intelligent boundaries. If you focus on me at X, you will know my “trajectories” with the o series of reasoning models. My first impression of o1/o1-pro is very negative. But as I gnawed my teeth and was driven by others’ good comments, I realized:** I’m using the wrong methods.** I wrote down all the thoughts that were passed down by @sama and quoted by @gdb.
The key I found was: ** Don’t “talk” it **.
It should be considered as a report generator**: Give it enough context, define the target, and then let it produce its own results. That’s the way I’m using o3 now. But this also raises the problem of assessing o3 pro.
It’s smarter, really smarter.
But if you don’t give it enough context, it won’t show its strength. I couldn’t ask it a simple question and it was shocked. And then I changed the way. Alexis, my co-founder, took the time to sort out all our past planning minutes, targets, even voice memos at Rainrop, and then let the o3-pro get this information for a plan. We were shaken. It created the kind of concrete plan and analysis that I’ve always wanted LLM to export** — including target targets, timetables, priorities, and clear indications of which should be abandoned. The plan for us is “reasonable”. But the plan given by O3Pro is not only specific, but also ** rooted in our own context** so that it** really changes the way we think about the future**.
It’s hard to see through evaluation.
The trial o3Pro made me realize that today’s models are very strong in isolation, and we don’t have a “simple test” to fully evaluate them. The real challenge is:** to integrate them into society**. Like an IQ with a high 12-year-old going to college. Smart is smart, but not a good employee if you can‘t adapt to society.
Today’s “integration” depends mainly on tools:
-
The ability of models to collaborate with humans, external data, and other AIs;
-
It is an excellent “thinker”, but it also needs to grow into an excellent “executor”.
O3 Pro really jumped into this:
-
Be demonstrably better able to understand the environment in which they live;
-
Accurate expression of the tools available to them;
-
Knowing when to ask for information from the outside world (rather than pretending to know);
-
Can choose the right tools to do the job.
o3 pro (left) vs o3 (right):
The o3 pro on the left is clearly stronger in understanding where he is.
From early use:
If you don’t give it a context, it‘ll have a tendency to think too much.
It is good at analysing and using tools, but it is not good at doing it directly**.
I think it’s an excellent “organizer”.
For example, there are some Clickhouse SQL problems, o3 doing better than o3Pro.
The results may vary from one person to another.
-
Claude Opus looked “very strong,” but never showed me evidence of it.
-
O3 Pro’s output is better,** it’s a completely different dimension**.
#<a href=”/tags/openai.html’ | prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a> is advancing the path of “enhanced learning vertically” (e.g. Deep Research, Codex): Teaching not only how to use tools, but also when to use tools**.
How to hint that the reasoning model hasn’t changed:
My o1 reminder guide is still applicable. The context is everything – it’s like feeding cookies to Cookie Monster. It’s a way to start the LLM memory, and it’s purposeful to make it more effective. System alerts are also extremely important. Models are now very “plastic”, so the “harnesses” that can teach models of their environment and objectives have a huge impact. It is this “tip frame” – model + tool + memory + method – that makes the AI product “good.” Cursor, for example, is the kind of mechanism that allows it to work “most of its time”.
Other fragmentary observations:
-
The impact of system alerts on model behaviour is significant (positive change);
-
significant differences between o3 Pro and o3;
-
<a href=”/tags/openai.html’ prepend: site.baseurl }}” class=”tag-link-inline”>OpenAI</a>’s “tool-enhanced reasoning” strategy is indeed ahead.